通过强化学习和官方API制作《星露谷物语》的自动钓鱼mod
通过强化学习和官方API制作《星露谷物语》的自动钓鱼mod
这是一个我已经断断续续地研究了很长一段时间的项目。在此项目之前我从未尝试过修改游戏,也从未成功训练过“真正的”强化学习代理(智能体)。所以这个项目挑战是:解决钓鱼这个问题的“状态空间”是什么。当使用一些简单的 RL 框架进行编码时,框架本身可以为我们提供代理、环境和奖励,我们不必考虑问题的建模部分。但是在游戏中,必须考虑模型将读取每一帧的状态以及模型将提供给游戏的输入。然后相应地收集合适的奖励,此外还必须确保模型在游戏中具有正确的视角(它只能看到玩家看到的东西),否则它可能只是学会利用错误或者根本不收敛。
我的目标是编写一个能读取钓鱼小游戏状态并完美玩游戏的代理。目标的结果是使用官方 Stardew Valley 的 modding API 用 C# 编写一个自动钓鱼的mod。该模块加载了一个用 Python 训练的序列化 DQN 模型。所以首先要从游戏中收集数据,然后用这些数据用 Pytorch 训练一个简单的 DQN。经过一些迭代后,可以使用 ONNX 生成一个序列化模型,然后从 C# 端加载模型,并在每一帧中接收钓鱼小游戏的状态作为输入,并(希望)在每一帧上输出正确的动作。
钓鱼迷你游戏这个代理是在SMAPI的帮助下编写的,SMAPI是Stardew Valley官方的mod API。API允许我在运行时访问游戏内存,并提供我所需要的一切去创造一个与游戏状态进行交互并实时向游戏提供输入的代理。
在钓鱼小游戏中,我们必须通过点击鼠标左键让“鱼钩”(一个绿色条)与移动的鱼对齐。鱼在这条竖线上无规律地移动,鱼钩条与鱼对齐时,绿色条就会填满一些,如果鱼成功逃离绿色条就会开始变空。当你填满绿色的条形图时,你会钓到鱼,当它绿条没有时鱼就跑了。
强化学习问题定义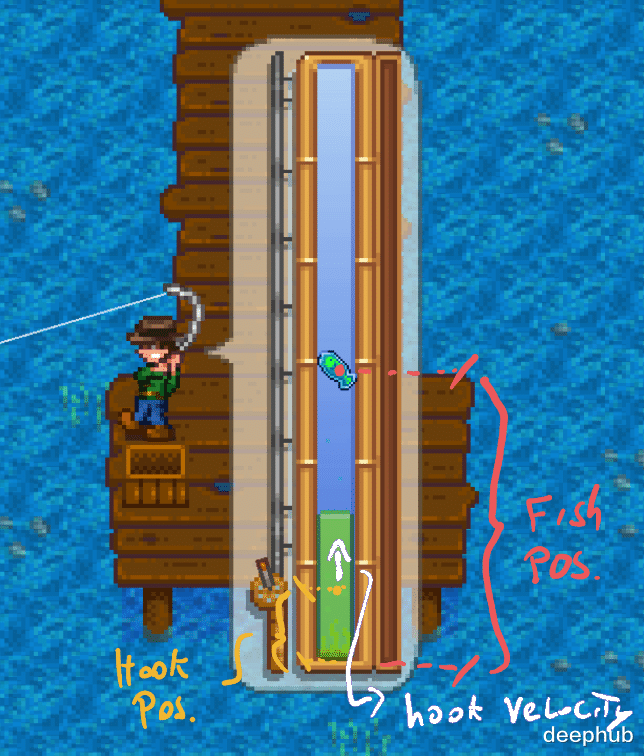
所以这里只需要每帧从游戏内存中读取这些特定属性并将它们保存为在第 t 帧的状态。通过API我们可以查看并从游戏内存中读取特定属性的代码,对于自动钓鱼,需要在钓鱼小游戏期间跟踪的 4 个变量。 “钩子”中心的位置、鱼的位置、钩子的速度和绿色条的填充量(这是奖励!)。 游戏内部使用的名称有点奇怪,以下是读取它们的代码。
/ Update State
// hook position
bobberBarPos = Helper.Reflection.GetField<float>(bar, "bobberBarPos").GetValue();
// fish position
bobberPosition = Helper.Reflection.GetField<float>(bar, "bobberPosition").GetValue();
// hook speed
bobberBarSpeed = Helper.Reflection.GetField<float>(bar, "bobberBarSpeed").GetValue();
// amount of green bar filled
distanceFromCatching = Helper.Reflection.GetField<float>(bar, "distanceFromCatching").GetValue();
前三个定义了我们的状态:
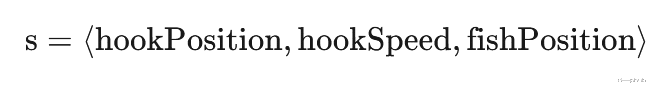
这是模型可以在每一帧上可以获取的状态,要将其设置为强化学习问题还需要使用奖励来指导训练。 奖励将是绿色条的填充量,这是里的变量名称为 distanceFromCatching。 这个值的范围从 0 到 1,正好非常适合作为奖励。
Replay MemoryReplay Memory是 Q-learning 中使用的一种技术,用于将训练与特定的“时间”去关联。 所以需要将状态转换存储在缓存中并通过缓存中随机抽取批次来训练模型而不是直接使用最新数据进行训练。 为了训练模型,我们需要 4 个数据,分别是当前状态、下一个状态、采取的行动和奖励:
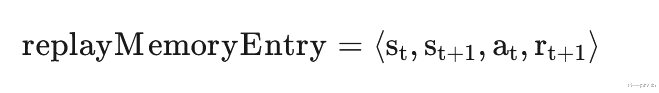
Q-learning 中关键问题是要获取曾经处于哪个状态和采取了哪些行动、到达哪个新的状态,以及执行这个行动中得到的奖励。有了这些数据,我们可以使用像价值迭代 (Value Iteration 一种动态规划算法)这样的简单算法将奖励从最终状态(获胜状态)开始分析,逐渐往回推直至推至所有状态。因此对于每个可能的状态,模型都会知道最大化其未来回报的方向。 但是我不会使用价值迭代来训练模型,因为真正的问题往往有太多的状态并且动态规划需要很长时间。
上面的价值迭代只是为了说明在 C# 中保存每个条目的方式。 这里使用缓存从最后一帧获取状态和动作,并将所有这些与当前帧的状态和奖励一起存储。
replayMemory[updateCounter,0] = OldState[0];
replayMemory[updateCounter,1] = OldState[1];
replayMemory[updateCounter,2] = OldState[2];
replayMemory[updateCounter,3] = NewState[0];
replayMemory[updateCounter,4] = NewState[1];
replayMemory[updateCounter,5] = NewState[2];
replayMemory[updateCounter,6] = reward;
replayMemory[updateCounter,7] = actionBuffer? 1 : 0;
所有这些数据都变成了一个巨大的 csv 文件,这样可以通过 Python 加载并用于训练 DQN 模型。
DQN 模型使用神经网络估计 Q-table的 Q-Learning称为Deep Q-Learning。这个方法在很多个 Pytorch 教程中都有很好的解释,我从里面复制了很多代码并为我们的问题对其进行了一些修改。主要思想是使用两个神经网络。一个将估计 Q(s,a) 的值(Policy Net),另一个将估计未来 Q-values的值(Target Net)。然后我们对这两个网络的差异进行反向传播。
这是 Q-Learning算法的基本方程。我们将使用一个网络来估计当前状态 Q(s,a) 的正确值,另一个将估计下一个状态的最大可能值。两个网络都使用随机值进行初始化,并且每隔几次迭代将Policy Net权重复制到Target Net。Policy Net则通过反向传播更新权重 ,通过反向传播这种,Policy Net 最终将学会估计这两个值。
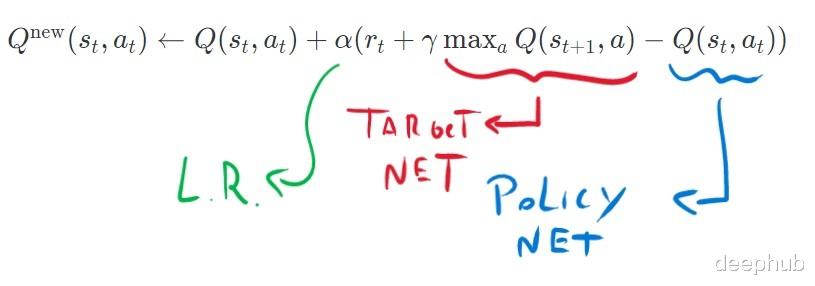
α 是学习率,
相关阅读
-
 这才叫热爱,游戏mod平均周产400个,《星露谷物语》mod精选推荐
这才叫热爱,游戏mod平均周产400个,《星露谷物语》mod精选推荐《星露谷物语》1.6版本更新后,不仅制作人变成加班狂魔,连续优化三个版本;就连许多mod的作者也开始疯狂输出。游戏自3月19日更新起,不算老mod的更新兼容,光是新mod的产量就达...
-
 一通百通,休闲种田游戏《星露谷物语》,N网MOD使用教程
一通百通,休闲种田游戏《星露谷物语》,N网MOD使用教程《星露谷物语》是一款2016年推出的像素风种田游戏。它凭借着丰富的游戏内容,以及活跃度极高的mod社区,常年来一直名列同类型游戏前茅。今天玩蛋就向大家分享,如何使用它的mod社区,...
-
 《星露谷物语》1.6版本更新现已在PC平台正式上线
《星露谷物语》1.6版本更新现已在PC平台正式上线《星露谷物语》1.6版本更新现已在PC(Steam、GOG)平台正式上线。Gamepass 版将在稍后推出。本次更新为游戏加入了全新的节日、后期内容、新的物品和制作配方、新农场类型...
-
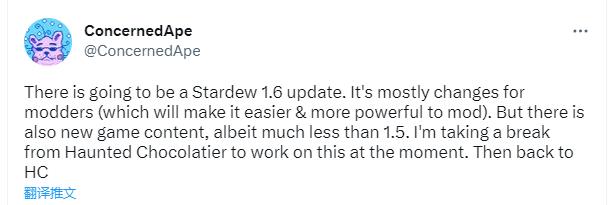 【星露谷又要有新内容玩啦!】《星露谷物语》的作者发推称正在为游戏制作1.6版本。
【星露谷又要有新内容玩啦!】《星露谷物语》的作者发推称正在为游戏制作1.6版本。【星露谷又要有新内容玩啦!】《星露谷物语》的作者发推称正在为游戏制作1.6版本。本次版本的更新主要针对模组制作者,也会有新内容的加入但比1.5版本要少一些。待更新完成后他会回归新作...
-
 Steamdeck官方版3月游戏排行榜公布 星露谷物语第一
Steamdeck官方版3月游戏排行榜公布 星露谷物语第一昨日,SteamDeck官方公布了2024年3月的热门游戏排行榜。最新版本1.6版更新的《星露谷物语》凭借其丰富的玩法和高质量的游戏体验,荣登榜首。紧随其后的是备受欢迎的卡牌游戏《...
-
 【《老滚5》玩家学习自制Mod 只为在游戏中纪念已逝母亲】一位名叫“VIVII”
【《老滚5》玩家学习自制Mod 只为在游戏中纪念已逝母亲】一位名叫“VIVII”【《老滚5》玩家学习自制Mod 只为在游戏中纪念已逝母亲】一位名叫“VIVII”的玩家制作了一个包含他过世母亲石碑的Mod,模组名为「纪念我的母亲(In memory of my ...
-
 《星露谷物语》新版本要出牧场了?这玩法太期待了
《星露谷物语》新版本要出牧场了?这玩法太期待了《星露谷物语》的开发者EricBarone最近一直通过“滴水式营销”的方式,逐渐透露了他称之为“彻底改变游戏”的1.6版本新内容。最新的消息是,游戏将新增一种全新的农场类型,似乎更...
-
 《星露谷物语》1.6大更新,是删号重新开始,还是继续体验游戏?
《星露谷物语》1.6大更新,是删号重新开始,还是继续体验游戏?相信对于许多热衷“种田”游戏的小伙伴来说,今天会是一个激动人心,又有点忧心的日子。激动的是经典种田游戏《星露谷物语》1.6版本更新内容很多;忧心的是那些打过许多mod的存档是否能完...
大家都在看
-
 马小桃邪魂师妆容乍现,邪魅火辣,最强魂帝实至名归
马小桃邪魂师妆容乍现,邪魅火辣,最强魂帝实至名归大家好,我是花花真世界。今天我们依旧来扒拉斗罗那些事儿,相比第一部斗罗大陆来说,第二部绝世唐门在制作上和剧情设定都更为精良,尤其是特效方面更加成熟,在最新剧情中,史莱克学院已经是迎...
-
 云顶之弈S11赛季 最新版本 最新阵容 同样的阵容 为什么王者组比我强
云顶之弈S11赛季 最新版本 最新阵容 同样的阵容 为什么王者组比我强天将凯隐细节教学前言你是不是也有很多困惑,为什么别人的凯隐这么厉害,或者说大数据上凯隐排名这么前,自己玩起来却强度一般呢?本期文章将会详细给您讲解凯隐机制部分玩家会选择把凯隐放在中...
-
 梦幻西游:如果抓鬼的小怪有8000血,策划就不用降低产环几率了
梦幻西游:如果抓鬼的小怪有8000血,策划就不用降低产环几率了游戏的意义就在于它能够给人带来快乐,大家好,我是小三,每天给大家分享游戏中的八卦趣事。周末的传闻太骚了,看的时候都担心角色被禁言不知道各位玩家在周六周日刷任务的时候有没有注意过传闻...
-
 一次更新造就全新三体人,T0恶霸诞生,脆皮、坦克同时被他克制
一次更新造就全新三体人,T0恶霸诞生,脆皮、坦克同时被他克制文/静海君仅用一次更新,大司命就成功蜕变为非ban即选的T0恶霸。大司命强在哪我说大司命强是有依据的。⑴正式服有加强在本周正式服的更新中,大司命迎来了一波大加强。其中,关于神巫状态...
-
 《鸣潮》新角色安可由旦白配音
《鸣潮》新角色安可由旦白配音库洛游戏的最新作品《鸣潮》近日公布了新角色共鸣者的形象,这位名叫安可的角色由旦白配音。《鸣潮》是一款由库洛游戏自主研发的二次元开放世界动作游戏,该游戏以高自由度的动作战斗玩法和丰富...
-
 超次元盘上游戏Steam上线 可操控棋子战斗
超次元盘上游戏Steam上线 可操控棋子战斗这款游戏名为《超次元盘上游戏》,是一款最近在Steam上线的新作。该游戏设定新颖,玩家可以在游戏中操控棋子进行战斗。游戏中包含了多种棋类玩法,如日本将棋、国际象棋、扑克和桌面游戏等...
-
 歧路旅人国服第五日进度,泰里翁卡池继续作妖,70抽歪出欧菲儿
歧路旅人国服第五日进度,泰里翁卡池继续作妖,70抽歪出欧菲儿歧路旅人国服进入第五天,游戏累计时长来到了40小时以上,五个城镇的地图指令和旅人故事都已经全部清掉,G哥的角色数量也来到了75个。简单总结第五日的进度,泰里翁卡池继续作妖,70抽歪...
-
 大话西游2:玄武星阵终极组合,睡杀无敌,宫位太漂亮了!
大话西游2:玄武星阵终极组合,睡杀无敌,宫位太漂亮了!亲爱的玩家们,我是老夏,一名大话西游2经典版的忠实拥趸。每天下午五点,这里将成为你们的欢乐源泉,我会为大家带来精彩的“每日牛图”系列。其中,你将看到妙趣横生的图片、出人意料的炼化结...
-
![[游戏资讯]《柯娜精神之桥》获ESRB评级,即将登陆XSX|S平台](http://dayu-img.uc.cn/columbus/img/oc/1002/6258ded2d03c63ec319d319869739256.png) [游戏资讯]《柯娜精神之桥》获ESRB评级,即将登陆XSX|S平台
[游戏资讯]《柯娜精神之桥》获ESRB评级,即将登陆XSX|S平台据报道,《柯娜:精神之桥》这款冒险游戏已经获得了ESRB的T级评价。适合青少年游玩。但是到目前为止,这款游戏还未公布会在Xbox平台上发布的确切消息。《柯娜:精神之桥》最初是在20...
-
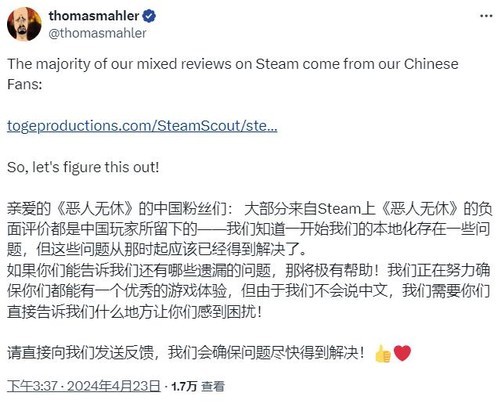 老外游戏差评成团 外挂才是最大元凶
老外游戏差评成团 外挂才是最大元凶近日,《恶意不息》工作室的CEO兼游戏创意总监thomasmahler在社交媒体上发布了一篇帖子。他希望向中国的玩家们寻求反馈意见。thomasmahler指出,目前《恶意不息》的...
- 众解说锐评LPL全局BP:Uzi充满期待Doinb想复出
- 老头杯队长确定!TheShy、Doinb都不参加
- 【LPL春决】复盘BLG如何破解TES百分百胜率的赛娜体系上
- 今年春天,Faker有多恐怖?反杀、开团、1v5,全程高能
- 反转了? 全乱了! LPL转会期shy哥上演去哪了
- 【LPL春决】复盘BLG如何破解TES赛娜体系下
- 最适合TheShy的版本来了,LPL夏季赛开启全局BP!
- 联盟正式官宣夏季赛赛制更改,全面效仿隔壁,启用全局BP模式
- LPL官方通报罚款并禁赛小乐言,IG回应被乐爷花式发工资
- 乐言被联盟禁赛罚款全过程,本人回应,IG又罚两月工资
- MSI入围赛赛程:TES 5月2日出战!
- H4cker直播确认夏季赛用全局BP,只有LPL用全局BP
- 2024英雄联盟季中冠军赛宣传片
小编推荐
-
 梦幻西游:欺负新人不懂,百级角色做师门,说单窗口日赚80米 2024-04-21 22:59:27
梦幻西游:欺负新人不懂,百级角色做师门,说单窗口日赚80米 2024-04-21 22:59:27 -
怪物对决活动不会玩?活动玩法和奖励看这篇文章就够了 2024-04-22 13:35:13
-
DNF:夏日套内容提前曝光!戒指最强附魔来了,后续有推出可能 2024-04-21 02:10:54
-
国服刚宣布回归,暴雪就联动仙剑?网友:死灵法师复活灵儿 2024-04-21 16:21:26
-
dnf雾神妮领主,愤怒的迷雾之布 ,老是跑来跑去的怎么打 2024-04-23 15:52:32
-
热血传奇:每个新手玩家都曾打过的bosss,尸王和骷髅精灵 2024-04-19 14:18:53
-
RNG股东爆料TES合同,除了JKL全员降薪,只为了一个目标 2024-04-21 13:39:57
-
笑影苏烈无敌强开帮助队伍拿下阶段首胜!RW 3-0 TTG 2024-04-20 23:49:23
-
Doinb被吐槽蹭热度,直播观看早期FPX视频,自己偷亲小天后逃走 2024-04-22 15:38:21
-
RNG或将围绕野辅重组,工作人员透露呼吸哥离开,AD在试训 2024-04-25 23:55:55