先后立项三次,“逼疯”郭炜炜的科幻机甲游戏经历了什么?
先后立项三次,“逼疯”郭炜炜的科幻机甲游戏经历了什么?

前不久,西山居在TGA上爆料了科幻机甲新作《解限机》(《Mecha BREAK》)。
看过葡萄君文章的读者可能知道,这款游戏是西山居在2019年就掏出的「机甲大作」《Code B.R.E.A.K.》,前段时间郭炜炜跟葡萄君聊到这款游戏时,还表示「目前已经是第三次重新立项了……我真的快疯掉了。」
巧的是,在TGA过去没几天,西山居引擎平台技术总监黄锦寿参与了今年的Unity Open Day广州站,并讲述了这款游戏的研发经历和渲染相关的技术攻坚情况。
以下为现场分享原文:

大家好,我是黄锦寿,来给大家介绍一下我们项目《解限机》(《Mecha BREAK》)里面的 Virtual Geometry(以下简称“VG”),分享一下我们在项目里面利用这个技术做了哪些东西,以及实现了哪些效果。

我们的游戏今年 12 月份在 TGA 亮相,《解限机》是一款以机甲为题材的多人对战 TPS 客户端游戏。游戏中有 3V3、6V6、大世界战场的对战玩法。其中大地图是一个 256 平方公里的庞大地图,可以容纳几十人一起对战。

我们为什么要给项目开发虚拟几何体?因为项目的需求是大世界地图,在实现庞大面积地图的同时,场景复杂度又非常高,而且我们的模型细节也非常丰富,精度也非常高。在视频中可以看到我们制作的战斗服务器很复杂,特效非常多,子弹的弹道都是实时计算、碰撞也都是精准碰撞检测。正因为模型精度高,所以制作需要多级的 LOD,美术资源制作工作量大,周期比较长。

用虚拟几何体,我们就可以解决以上的几个问题。用了这个技术以后,我们只需要制作高精度模型就好了,美术不需要再为制作 LOD 模型浪费工作量,因为 LOD 模型通过程序生成会比人力手工做更快、更好一点。因为我们的战斗非常复杂,GPU 的计算非常耗费,所以我们的想法是尽量把渲染相关的东西交给 GPU 来做,例如模型的裁剪。所以我们还开发一套 GPU 的渲染管线,把原本由 CPU 来做的裁剪、LOD 计算、排序等操作交给 GPU 来负责计算。
因为我们不用 MESH,而是模型的数据直接存在显存里,所以可以减少一定内存的使用。而且这样我们对于三角面的数量限制,就可以实现几何级数的突破,不再受到三角面数量的影响成为渲染效率的瓶颈。虚拟几何技术就有点像虚拟贴图一样,把 MESH 切分成很多 Cluster 等不同的部位,根据不同的距离来实时流式加载,只有需要级别的 Cluster 才会被载入到系统中去。

上面是一个支持骨骼模型动画,传统的 GPU 其实不同的 MESH 是没办法做到合批渲染的,我们用了虚拟几何体,也对骨骼动画做了特殊的支持。并且我们这一套渲染管线也支持 HDRP、URP,还有多平台的 PC、安卓、iOS,主机平台的 XBOX、PS5 在上面都是可以正常运行的。
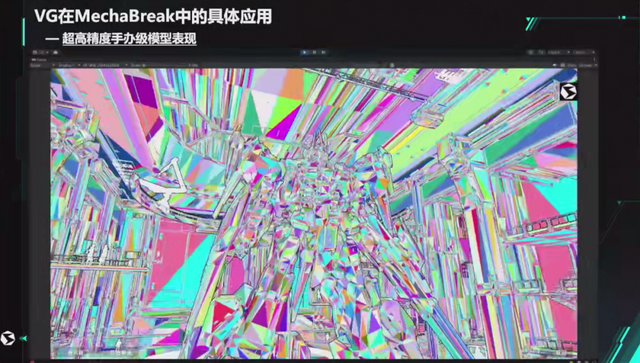
这是我们游戏机甲里面使用到的 VG 演示效果,机甲支持涂装系统,每个玩家可以有独立的材质,可以高自由度定制每台机甲的效果,这是我们虚拟几何体三角面片的模式。可以比较直观的看出,在机甲模型距离镜头远近的时候,会有 LOD 的切换,但是在实际的游戏来看是看不太出来有 LOD 明显跳变的。
游戏的植被系统是为项目专门定制化开发,让项目的植被项目系统支持 VG,我们游戏里所有的树和草都是通过 VG 渲染,并且还支持交互。

这是刚才说的植被系统在远处是使用了 IMPOSTER,近处可以看到是实体模型的树,远处是变成一个 IMPOSTER,这些植被也支持可破坏、交互,这些碰撞检测都是用 GPU 来支持的。
游戏里子弹打的每一棵树都是交给 GPU 来实时做碰撞检测,现在展示的是单人在打,其实我们游戏里面,是有多名玩家可以同时打,有很多数量的子弹。子弹的计算量是非常高的,所以我们把它利用 GPU 的并行计算来做碰撞检测,提高它的检测效率。可以支持大量的子弹同时并发做高效精准的碰撞检测。
这是我们游戏里面的一些机甲,每台机甲都是不一样的,不管是 MESH 还是材质、表现,种类是完全不一样的,但是在这个场景下,可以看到这些角色全都是一次绘制完的。不像传统的 Instance 是一个机甲类型绘制一次,现在是不同的类型都全部一次画完,而且拉远拉近会有自动的 LOD 切换。

我简单介绍一下这个是怎么做的,以及大概的原理。以前是用传统的 GPU SKINNING,要把动作烘培到贴图上,但是这样的话,动作融合、IK、RIG动作融合,都没有办法使用。因为我们的游戏对动作要求比较高,所以必须要使用这些功能。为了解决这问题,我们决定在这些动作系统计算完骨骼动画后,再把数据上传到 GPU 显存中,在 GPU 里面做蒙皮动画计算。最后在这一个 Drawcall 里面通过 VG 渲染,单个 DrawCall 全部绘制上去。就算同一个机甲,玩家可以有不同的涂装,有不同的纹理,不同的颜色,这些都是可以支持的。


这个就是我们刚才放的 40-50 个不同的机甲,单个 Drawcall 就可以一次画完了,要满足这个条件,这些机甲必须要用同一个 Shader,材质可以不一样,但是这个 Shader 必须要一样。骨骼数据、材质参数,用 Buffer 传到 GPU 进去,其实跟 GPU Skinning 一样也是在 VS 里面做蒙皮计算。骨骼动画的运算,和 Unity 原生的动画更新流程差不多,也是多线程里面计算完了之后,上传到 GPU 里面。

这是我们之前做的一个测试,大概放了 200 个模型,如果直接放这样的模型,不同 MESH 没有做合批渲染的时候,大概只有 40 帧左右;转化为 VG 之后,单次 DrawCallp 完成所有 Mesh 的绘制可以有 1 倍的性能提升。右边的图,其实是单 Drawcall 就把 200 个机甲全部绘制完了。

这里是可以看一下演示的,这个场景的面数非常高,可以看到这里的每一片叶子都是用的几十个面做的建模,我只是为了演示虚拟几何体的渲染性能,所以使用一个精度非常高(超出游戏资源规范)的树模型放到场景里。
这个场景是一个非常复杂的场景,上面植被加上建筑已经超过上万个,树是超高精度的、超过 375 万面的模型。这个树是自动化生成的,可能放了几百上千的植被的树,单场景里面应该是超过 10 亿面,如果算这个统计,估计可以上几十亿的三角面片都有的。但是由于有虚拟几何体的技术,我们就可以在面数上稍微放松一点,美术可以有更大的发挥空间。

这个是我们做 VG 的调试模式,因为我们左边第一个的是 Triangle 模式,是每个模型的三角面片的情况;中间是 cluster(等一下可能会讲到 cluster 的概念,它会把模型每一个切分成多个部分);第三个是 material id 可以看用了多少 Drawcall,不同的 Material 是不同的颜色。下面比较特别的是 Miplevel,当前显示的 LOD 级别,全红是 D0 最高级别的;下面中间的是 Max Miplevel,代表这个模型生成了多少级 LOD,取决于模型精度。我们在生成 VG 数据的时候,就已经生成完了,这就相当于你的面数非常高,可能生成的级别比较多一点,15、16 级都有可能;最后一个是测距模式,可以鼠标点在中间,看到当前这个物件距离镜头的距离是多少,我们是用来做调试,这个物件在什么距离会显示什么级别才合适,辅助我们做调试用的。

我演示一下这个场景 VG 的效果,现在画面里面看到的模型,都是虚拟几何体(Virtual Geometry)。

我们简单说一下这个虚拟几何体的渲染管线的实现原理。主要分两部分:第一部分是模型的切分和 LOD 的生成,另外一部分是搭建完整的 GPU 场景(即 GPU 渲染管线),要包括数据上传、裁剪剔除、LOD 计算,排序、渲染,其实和 CPU 渲染管线是一样的,就是全部都交由 GPU 来做完。不过它比传统 CPU 管线的裁剪部分多了一个步骤,除了 Instance 级别裁剪,还有 Cluster 级别的裁剪,在裁剪过程中要计算每个可见的 Cluster 当前的 LOD 值是多少,以此来决定该 Cluster 在屏幕中显示的时候,需要显示哪个级别的 Cluster,才加载那个级别的 Cluster 数据,再上传到 GPU 里面去。然后我们要对所有可见的 Cluster 按材质进行排序,再根据材质来进行渲染。

这里说一下刚才说的 Cluster,我们说的 Cluster 其实就是把一个整个 MESH 切分成了 N*N 个小模型,每个小模型就是一个 Cluster。切分完之后再分组,对每一组进行锁边,来做减面,减面后再切分 Cluster,再分组减面,循环以上步骤,一直生成完最低级别的 LOD 数据。锁边的作用是为了保证在 LOD 切换的时候,不会出现两个级别之间的接缝连接不上,出现对应不上的情况,能够保证它的边界是无缝衔接出来的。这样才能做到一个模型里面,可以同时显示多个级别的 Cluster LOD,比如一个模型里面,我身体可以是 LOD 0,头可以是 LOD 2。取决于你看到是哪个位置。

这幅图会直观一点,切分 Cluster 之后会有不同颜色。右边不同颜色的就是一个大块的,就相当于把包含里面的 Cluster 分在一组,分好组之后就把这个组里面的 Cluster 减面,可以看到右面的模型面数是非常高的,进行减面后,就只剩原来的一半面数,然后组内重新切分 Cluster,切分后新的 Cluster 再重新分组,如此循环,直到生成最低精度的模型。

总结就是根据第一步生成的 Cluster,进行分组减面生成下一级 LOD 的 Cluster,每级面数减少一半。原则是切出来的 Cluster 保持的面积尽可能接近。
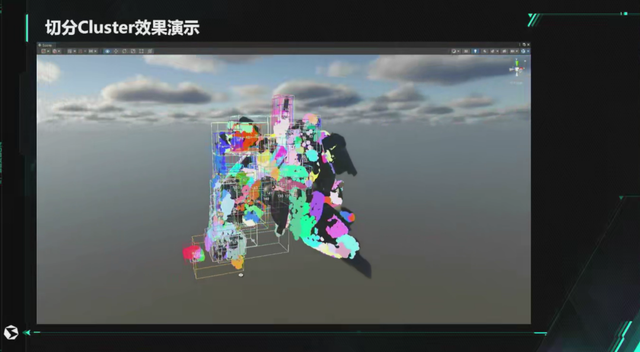
这是一个 Cluster 切分的演示,这就是一个整模通过我们的算法对它做 Cluster 的切分,每一个不同的色块都切分成子的 MESH,就是我们说的 Cluster,里面有包围盒数据,这些数据就是为我们 GPU 管线做裁剪使用的。
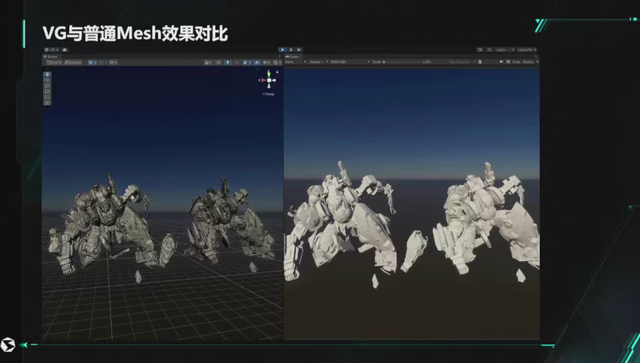
这里是演示了普通的 MESH 和 VG 的 MESH 的区别,拉远的时候模型会消失,是因为它超过了我们镜头裁剪距离,可以不渲染了,所以 VG 模型就直接不渲染了。我们支持遮蔽裁剪,被物件挡住也是不会渲染的,还有视锥裁剪,模型的一部分离开了镜头之外,那一部分就不渲染了。如果是传统的 LOD,或者是传统的裁剪,这个模型是整模,看到一个手指都会整个模型渲染。我们使用 VG 之后,就可以做到“看啥渲啥”,只渲染我看到的头部或者手的一部分,看不到的部位可以不渲染,这大大节省了渲染的三角面数,提高渲染性能。

这个就是我们在用普通模型,以刚才的模型为例,大概是 25 万面,原始内存是 14.5M,本地磁盘是 10M 左右。我们转成 VG 之后,我们存成自己单独的格式,文件大小是 6.1M,而且是包含 14 级 LOD,这个模型可以一直 LOD 到第 14 级,即便这样也只有 6M,压缩率是原来大概的 65%。如果加上 LOD 数据的 MESH 来比较,压缩率会超过 50%,可能会更高一点。因为原来的只有 LOD0 并没有 LOD1、2、3。而 VG 的模型是包含了 LOD14 级,而且 VG 不占用内存,数据只存在显存当中,对于内存的压力来说,可以大大释放了。

这个是我们 GPU 场景大概的渲染流程。
思路是这样的,上面的 GPUScene 线程就是有点类似 Unity 的渲染线程,下面的主线程是发起 GPU 相关的指令,如添加、删除 VG 对象、位置更新、裁剪回读、数据上传等操作指令 ,这些指令发起后,实际是交给 GPUScene 线程做处理,所有具体的操作,数据处理,上传数据,跟 GPU 相关的操作都在此线程中完成。最下面的 GPU 才是我们真正的 GPU 单元的处理任务,俗称显卡的计算。GPU 需要处理数据解压、裁剪、排序、渲染,这里相当于一条完整的渲染管线流程都是在 GPU 里面完成。CPU 只需要把模型的数据上传到 GPU 里面去,其他的事情都交给了 GPU。这里使用 GPUScene 线程来做数据处理,目的是部分渲染相关的处理需要等 GPU 计算结果,放到子线程里做,可以跟主线程中的一些逻辑计算并行处理。充分利用 GPU 和 CPU 时间。减少相互等待的而造成的算力浪费。

这是我们的显存的使用量,从图中可以算出整个 VG 的系统所需的显存大小,图中你看到最大的 Buffer 是 134M,我们称它为 Page Buffer,它就是整个 VG 系统模型数据的总 Buffer,它要把整个系统,场景里面所看到的模型的 MESH 数据都是放在里面。除了 Page Buffer 还有一些裁剪的列表的 Buffer,各种不同的 Buffer 的数据加起来,不超过 300M。而且这样的话,我们是不需要再加载以前的 MESH 数据,即 CPU 里我们不需要存储任何模型数据。
这是我们的一个场景,因为我们的资源量非常大,以前还没有使用 VG 的时候,MESH 数据占用内存 1100M,改成 VG 之后,因为 MESH 已经不需要了,都把实时的数据压缩到 GPU 的 Page Buffer 里。我们模型数量很多,并且都很大,加载单个 MESH 10M 内存就被占用了。现在只有镜头渲染到需要显示级别的数据,才能上传到显存里面,而且显存 Buffer 是一个共享池,是可以循环使用的。从数据上来看,比之前节约了 900M 的内存。
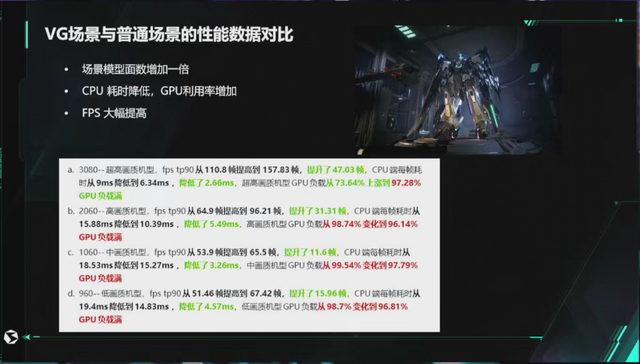
这是一个场景的性能的对比,我们刚才视频里演示的,以前普通模型的场景在 3080 可以跑到 110 多帧,960 显卡可以跑 51 帧,我们换成 VG(即场景中所有模型都不使用 MESH,而是虚拟几何体),FPS的提升分别是 43% 和 31%。因为所有的裁剪、LOD 计算都从 CPU 放到了 GPU,所以 GPU 负载都是有上涨的,从 70% 上升到 97%。但是比较可观的是 CPU 的耗时,都有明显的降低,3060 的机器上降低了 2.66 毫秒,在 2060 的机器上甚至降了 5.49 毫秒,960 的机器也降低了 4.57 毫秒。对 CPU 有很大的释放,普遍有 20% - 30% 的 CPU 性能提升。我们就可以把 CPU 的计算能力用于游戏逻辑等其他地方上,不再由渲染占用这一部分的 CPU 性能。

这里是我们的手机版本的视频,虚拟几何体已经把它支持到 iOS 和安卓上,其实 XBOX 和 PS5 都可以使用,但这次没有录制这个视频。用到的数据和 PC 上一样的,一套流程处理的数据就可以在 PC 版和手机版上使用,模型只做一套资源,也不需要专门为手机做优化制作不同精度的模型资源,我们只要调一下参数,让它显示的精度级别不一样。
今天我要介绍的就是这么多了,这里是我们最开始一个想法的视频演示,是一个 VGBOX 的模型,无限细分,每一个级别就是递减一半的面。而且是支持镜头裁剪的,还有遮蔽裁剪,实现镜头看到的才会渲染出来,镜头看不到的就不渲染,根据不同距离来决定显示精度,一开始是抱着这样的想法来做的。这个 Demo 主要是为了快速验证 Virtual Geometry 这样的 GPU Driven 渲染管线能不能在 Unity 里实现。

今天的分享就到这里,谢谢大家!

相关阅读
-
 本周游戏简讯(2230604)《暗黑4》豪华版抢先体验,西山居《Code B.R.E.A.K.》第三次立项
本周游戏简讯(2230604)《暗黑4》豪华版抢先体验,西山居《Code B.R.E.A.K.》第三次立项西山居《Code B.R.E.A.K.》第三次立项最近,据报道,西山居CEO郭炜炜在采访中表示,他们的全新科幻机甲端游《Code B.R.E.A.K.》目前已进行第三次重新立项。该...
-
 国产机甲题材新作《解限机》倍受期待,郭炜炜首曝研发历程
国产机甲题材新作《解限机》倍受期待,郭炜炜首曝研发历程前段时间,由西山居制作的机甲新作《解限机》进行了短暂的首测之后,不少机甲迷对于这款国内为数不多的科幻机甲题材表示相当的期待,与此同时不少海外玩家,甚至是高达粉更是将游戏当做“敲打”...
-
 憋了八年,不惜烧掉数亿,郭炜炜只想争口气
憋了八年,不惜烧掉数亿,郭炜炜只想争口气很多人认为郭炜炜有些过气了,在《剑网3》之后一直没有第二款大成的产品。 而《解限机》(《Mecha BREAK》)作为郭炜炜的最新作品,被不少人视为整个西山居的关键之作,也是郭炜...
-
 剑网3赛事被指不公,金山软件高管郭炜炜震怒,要求必须规范整改
剑网3赛事被指不公,金山软件高管郭炜炜震怒,要求必须规范整改出品:子弹财经4月9日消息,今天“郭炜炜 做不好就不要做了”这一话题登上微博热搜。原来是金山软件高级副总裁、西山居CEO郭炜炜在网上怒斥自家公司的剑网3赛事组。他写道:“赛事如果做...
-
 郭炜炜让利9位数RMB,为无界开路!唯一国产全华班端游即将上线!
郭炜炜让利9位数RMB,为无界开路!唯一国产全华班端游即将上线!在刚刚过去的剑网三2023-2024年年夜饭发布会现场,郭炜炜上来就甩出“王炸“,让利9位数RMB。为了庆祝四月份即将上线的剑网3无界,明年,剑网3将直接以每年1亿元现金的点卡收费...
-
 《剑网 3》全平台旗舰版立项:基于灵境引擎制作,端手游互通
《剑网 3》全平台旗舰版立项:基于灵境引擎制作,端手游互通IT之家11月22日消息,《剑网3》制作人郭炜炜宣布《剑网3》全平台旗舰版已经正式立项!移植手游将和PC端重制版互通,手游预计2024年4月发布。据介绍,《剑网3》旗舰重制版基于灵...
-
 西山居成最终赢家?CSGO饰品崩盘后,大批商人涌入剑网3!
西山居成最终赢家?CSGO饰品崩盘后,大批商人涌入剑网3!CSGO饰品市场崩盘,CF没赚到玩家,剑网3却先把钱给挣了?这普天之下怎么会有如此好事全都给郭炜炜摊上啊???俗话说得好,好事不出门坏事传千里,这句话放在游戏圈也完全适用——CSG...
-
 MMO游戏开始走下坡路?郭炜炜亲自出手,剑三CE测试打破僵局!
MMO游戏开始走下坡路?郭炜炜亲自出手,剑三CE测试打破僵局!今年游戏圈的几场大地震,差点把国内的游戏玩家给震麻了——首先是去年尝到暗黑手游甜头的暴雪,也许是觉得自己翅膀硬了,出人意料地跟网易闹掰。运营了18年的国内第一MMORPG魔兽国服,...
大家都在看
-
 大话西游2:挂机烧香,回来一群人M我,这是得啥高级奖励?
大话西游2:挂机烧香,回来一群人M我,这是得啥高级奖励?亲爱的玩家们,我是老夏,一名大话西游2经典版的忠实拥趸。每天下午五点,这里将成为你们的欢乐源泉,我会为大家带来精彩的“每日牛图”系列。其中,你将看到妙趣横生的图片、出人意料的炼化结...
-
 歧路旅人大陆的霸者主要玩什么?玩养成还是玩剧情,一篇说清楚
歧路旅人大陆的霸者主要玩什么?玩养成还是玩剧情,一篇说清楚《歧路旅人大陆的霸者》国服说话就要开了,从不断放出的宣传片中朋友们大概可以提取到如下信息。看似2D却又有3D感觉的像素风格画面,四个穿着打扮不一的像素小人在各种地图上乱跑,可8人出...
-
 AME幽鬼全图降临 XM雷云下无人生还 XG2-0击败Aurora晋级
AME幽鬼全图降临 XM雷云下无人生还 XG2-0击败Aurora晋级直播吧5月12日讯 PGL瓦拉几亚S1小组赛瑞士轮第三轮,同是2-0的XG对上了Aurora。AME虚空带队打出完美团拿下第一局。双方BP:天辉XG:XXS末日、Dy祸乱、AME幽...
-
 《超越巅峰2》世嘉MD最华丽赛车游戏,当年买到最强发动机了吗?
《超越巅峰2》世嘉MD最华丽赛车游戏,当年买到最强发动机了吗?这是老男孩游戏盒的第888篇原创,作者@小chen在80、90年代一路走来的玩家还是比较幸运的,不像现在这样网游遍地打枪、MOBA、MMORPG,应用商店就那么几款游戏一玩玩十年,...
-
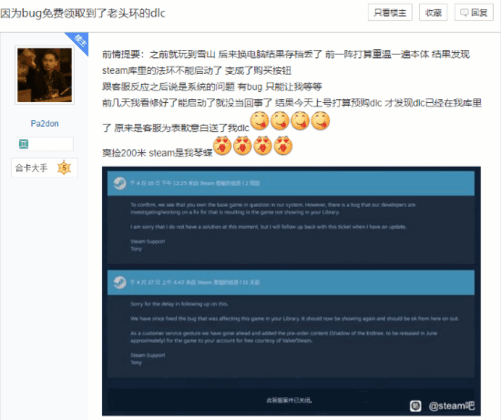 《老头环》玩家进不去游戏 官方赠送DLC表歉意
《老头环》玩家进不去游戏 官方赠送DLC表歉意近日,一名Steam用户在使用时遇到了一款名为《艾尔登法环》的游戏出现的bug。并且无法正常游玩。虽然官方客服表示需要等待以解决这个问题,但该用户仍然心有不甘。然而,在问题得到解决...
-
 部分主播已接单推广单子,国服整装待发,魔兽世界何时归来?
部分主播已接单推广单子,国服整装待发,魔兽世界何时归来?农工可以确定的一件事情就是魔兽世界国服六月份大概率会有一款游戏开服,但是具体是什么游戏暂时无法得知。唯一可以确定的一件事情就是部分头部主播接单了商单,而这个商单是关于暴雪游戏的单子...
-
 5Ban中单!沙皇倒了4个沙兵没用!BLG击败T1晋级胜决
5Ban中单!沙皇倒了4个沙兵没用!BLG击败T1晋级胜决★游戏马蹄铁原创BLG击败T1BLG今天打破质疑,证明他们确实是因为换线问题才和PSG打满了Bo5。而面对同样换线不太行的T1,加上Faker今天状态低迷,BLG最终以3-1获胜晋...
-
 传奇3暗黑版手游:装备的强化攻略,武器炼制玩法解析!
传奇3暗黑版手游:装备的强化攻略,武器炼制玩法解析!《传奇3》作为一款备受玩家热爱的游戏,其中砸武器可谓是每一位玩家乐此不疲的日常活动。每个玩家都有着自己独特的砸武器配方,甚至有些人能够成功砸出顶级上限的武器。尽管有人认为这纯粹是运...
-
 韩国网友锐评T1 3-1 TL: 感谢Corejj!如此状态,怕是要被G2零封
韩国网友锐评T1 3-1 TL: 感谢Corejj!如此状态,怕是要被G2零封2024 成都MSI季中赛败者组半决赛T1 vs TL,参赛双方在为观众奉献了一场时长接近三个小时的“厨王争霸赛”之后,最终还是T1战队技高一筹,以3-1的比分有惊无险地击败了TL...
-
 DNF:CP武器红眼加点方案解析!和改版前变化不大,仅供参考
DNF:CP武器红眼加点方案解析!和改版前变化不大,仅供参考红眼作为国服基数最大的职业之一,在5月版本上线之后,CP武器也是得到改版了!在改版之后,不仅增加了10%技攻、增强了血爆、大十字15%的攻击力。同时还将血剑,狂斩的攻击力从30%变...
- 十万人打出10的完美评分!感谢Bin拯救BLG以及LPL
- 久哥复盘BLG战胜T1:Zeus没赢过Bin他凭什么是世一上
- 传奇捕飞人阿Bin,上一次击败Faker还是上一次
- 阿bin青钢影踢爆T1挺进决赛
- 我超Bin!各赛区解说看Bin青钢影EW闪E擒杀Faker
- 就算他faker躲在天涯海角,海克斯最后的通牒也会锁定你!
- 完全披萨!各赛区解说看Bin青钢影一留四BLG战胜T1
- 超级Bin青钢影踢穿T1!BLG拒绝复刻S7冲进决赛
- Zeus野区迷路遭到逮捕 Faker扎克姗姗来迟无力回天
- Knight炸药包瞬秒赛娜 奎桑提佛耶戈主宰残局扳平比分
- Zeus奎桑提团战肆意游龙 Faker捏死大招完成收割
- Oner两标全中单吃Xun Elk赛娜光速支援将其留下
- ON牺牲自己拖住Zeus Bin天秀进场切后双杀
小编推荐
-
 热血传奇:防御力极高模仿却很拉胯的小怪,深受战士厌恶 2024-05-11 14:22:46
热血传奇:防御力极高模仿却很拉胯的小怪,深受战士厌恶 2024-05-11 14:22:46 -
在大逃杀对战中存活到最后,成为名副其实的暴食王! 2024-05-11 11:35:41
-
姜维接棒诸葛亮?数值怪只需要狂叠属性!【三国志战棋版】 2024-05-14 09:01:15
-
ON:打GEN会限制他们BP;我们五个人的目标只有——冠军! 2024-05-18 23:11:29
-
朵莉亚520皮肤被吐槽“冤种”皮肤,买到手却不能用,确实挺痛苦 2024-05-18 01:06:43
-
这款游戏再迎来新一波期待 《黑神话:悟空》中英翻译引发网友热议 2024-05-19 00:41:52
-
崩铁2.3卡池最新情况!3大人气美女齐聚,流萤幽默改动玩家不买账 2024-05-15 07:22:19
-
三国杀:别再拖累你的团队了!这些武将真别选,太坑爹! 2024-05-17 18:25:09
-
炉石传说:神铜须补丁实装,幻变模式回归! 2024-05-16 08:52:33
-
梦幻西游:抓鬼操作手赚钱太容易了,接三组号能做到月入过万 2024-05-17 14:13:42